Wednesday October 20th 2004
Finance : second lecture (part two).
Table of contents:
Simple and weighted averages :
In the first part of this lecture we saw that a weighted average can be viewed as a variety of simple of average where we repeat the elements in the calculation according to their weight :
the weighted average
100*30% + 200*70%
is nothing more than the simple average
(100 + 100 + 100 + 200 + 200 + 200 + 200 + 200 + 200 + 200) / 10
We saw that the expectation of a random variable X is defined (and computed) as the weighted average of the possible values ai's of the outcomes, weighted with their respective probabilities.
And we saw that it is a natural definition because it is (approximately) the value taken by the simple average of the outcomes x1, x2, x3, .... , xn of X in a large number of replications of the experiment producing X.
Z can take the values $35, $60, $70 and $95, with respective probabilities 15%, 30%, 25%, 30%.
What is the mean of Z (the weighted average of the possible values Z can take, weighted with their probabilities) ?
Answer : $69.25
This is the exact mean of Z. Once again note that this does not have to be one of the possible outcomes of Z.
And if we produce many many outcomes of Z : z1, z2, z3, ...., z5000 , the simple average of the zi's will be very close to $69.25.
Past history of a random variable :
If we had only known a past history of Z - what I mean by "a past history of Z" is a series of past outcomes of Z ( z1, z2, z3, ...., z5000 ) - and had not known the actual probabilities of each possible outcome of Z, we would have been in a situation closer to real situations in Finance.
Financial magazines and financial websites :
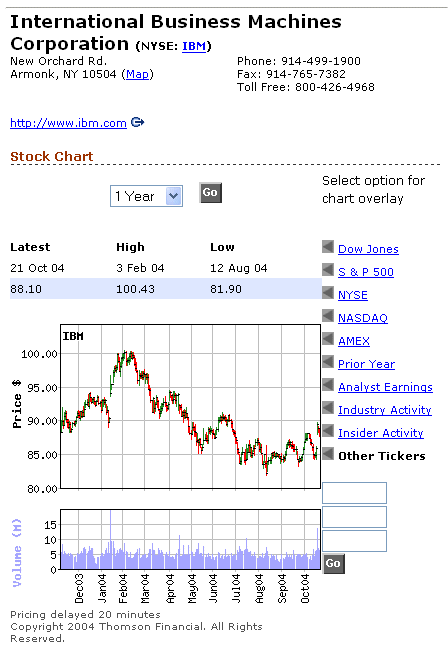
Financial magazines and financial websites provide us with plenty of information about past history of securities, but they cannot give us exact probabilities like for instance Pr{IBM stock price in mid-2005 ≥ $90}
Hoover's online is one of the many well known financial websites. Here is the information it gives about IBM stock price on the NYSE
From this information (and other sources) it is our job, as investors, to figure out what we think will be the behavior of IBM price next year, and decide whether we want to buy some stocks or not.
The probabilistic model for the behavior of IBM stock price is a bit different from just one discrete random variable being "tossed" every day.
Estimation of the probabilities of a discrete RV :
Back to a discrete random variable X that can take the values a1, a2, .... ap.
When we only have a past history of X, we can estimate the probabilities Pr{X = ai} for i = 1 to p. It is simple enough :
for example, to estimate Pr{X = a3}, in the long series x1, x2, x3, .... , xn, we count how many of the xi's are equal to a3 and divide this count by n.
We know from our everyday experience that this gives a good estimate of Pr{X = a3} (It can be "proved", but we are not much concerned with "proofs" here.)
Then, once we have our set of estimated Pr{X = ai} we can work with them as if they were the real ones. For a die, for instance, supposing we didn't know that the real probabilities are 1/6, 1/6, ... 1/6, we could be working with 15%, 16%, 18%, 17%, 15% and 19% obtained from a long series of past throws.
We can even compute an estimated mean of X, and, lo and behold, it produces
(x1 + x2 + x3 + .... xn) / n
At the moment in the United States there are frequent polls carried out to forecast who will be elected president, of Bush or Kerry.
Simple polls are easy to understand : suppose that out of the 100 million or so Americans that will actually vote, the proportion in favor of Bush is p, and the proportion in favor of Kerry is (1-p). How to estimate the parameter p ?
The obvious and usual way to proceed is to choose at random n persons, in the population of voters, and ask them who they will vote for. This will give us n outcomes of a random variable V that can take only two values "b" or "k".
Count the number of "b" in the series of n outcomes of V, and divide by n. This gives us an estimate of p.
It can be calculated that when n is around 1000 the estimate of p becomes reasonably good (it becomes very likely that we make an error no larger than a one or two percentage points).
That is why most polls, conducted to estimate all sorts of political probabilities, sample about 1000 people. (But it is quite possible to carry out a sampling with only 500 xi's, if we are satisfied with less accuracy and we don't want to incur the cost of sampling 1000 people.)
Several remarks ought to be made though :
A paradox about democracy : candidates don't spend much time trying to convince the people that will vote for them anyway, and they don't spend much time either trying to convince people that won't vote for them anyway. They concentrate on the undecided people. These are only a fraction of the electorate. So it can be said that the president is actually chosen by only a fraction, sometimes a small fraction of the population.
The four situations in which we deal with random variables :
We saw in the first part of the lecture the following table, presenting the four situations in which we deal with random variables :
| We know everything about the probabilities | We only know a past series of outcomes | |
| Discrete random variables |
|
|
| Continuous random variables |
|
|
We have now completed, for the time being, our study of the first row : discrete random variables, either in a situation where we actually know the "underlying probabilities", or in a situation where we only know a series of past outcomes, and we use it to estimates everything else.
When I need to introduce new concepts about random variables, I will always describe them first for a RV in the top left cell.
Now is time to talk about continuous random variables.
Continuous random variables can take any value in a range of real numbers, for instance, if we deal with cash flows, any figure between, say, $0 and $30000, or if we deal with profitabilities, any figure between, for instance, -200% and +200% The range of possible outcomes is now infinite and continuous.
Real numbers are those numbers that sometimes require many decimal places to give the exact figure.
Profitability of a US portfolio of industrial securities :
What is a portfolio of securities ?
Consider two securities S and T, traded in the stockmarket. Suppose today S sells for $5 and T sells for $15. Each of these prices, as we know, is the equilibrium reached between buyers and sellers. Stockmarkets are one place where the law of supply and demand, that you learned in Economics, applies perfectly.
If we have a sum of money to spend in the stock market, say $1000 to make calculations simple, then we can purchase a certain number of S and a certain number of T. For instance we can purchase 80 S, and 40 T, because this costs 80*$5 + 40*$15 = $1000.
80S + 40T is called a portfolio of securities, made of 80 S and 40 T.
Next year, each security will have a new value, for instance $5.5 and $18. Then the new value of the portfolio will be $440 + $720 = $1180, therefore its profitability will turn out to be 18%.
We can make portfolios with more than two securities.
Some private stockmarket agencies compute the price of large portfolios of securities "behaving like the whole market". The two most famous are Dow Jones and Standard and Poor's. They publish their profitability data, that are called their indices. They also publish the mix of securities they use. For instance in the mid 20's the Dow Jones index was the profitability of a portfolio made of the following 20 securities :
| Allied Chemical | American Locomotive |
| American Can | American Smelting |
| American Car & Foundry | American Sugar |
| American Telephone & Telegraph | Sears, Roebuck |
| American Tobacco | Texas Corp. |
| General Electric | United Drug |
| General Motors | U.S. Rubber |
| International Harvester | U.S. Steel |
| Mack Trucks | Western Union |
| Paramount Famous Lasky | Woolworth |
Today's hand out gives you the Standard and Poor's index over 73 years from 1926 (included) until 1998.
The numbers can be thought of as 73 outcomes of a continuous random variable R. We shall study this random variable, after a brief detour via theory.
The problem we have to get around, concerning continuous RV :
Back to some theory.
Even though continuous random variables have outcomes, just like discrete RV, the set of possible outcomes is now infinite and continuous, and the probability of each specific outcome is zero.
If we have a portfolio of securities and we call X its profitability in one year, the probability that X be any precise figure is zero :
Pr{X = 72.32653746...%} = 0
In order to get around this problem we shall introduce the concept of density of probability in the vicinity of any possible outcome of X.
This pertains to the field of Calculus.
We shall not use Calculus in this Finance course, so we can relax and take a look, if we like, at the next sections just for our culture. I will try to make them as simple as possible. And I will introduce some historical notes to give them more life.
Study becomes mandatory again only when we reach the section concerned with histograms.
Cumulative distribution of probability :
For any random variable X, taking values in the whole range of numbers from - ∞ to + ∞, we define the function F as follows :
for any possible outcome x,
F(x) = Pr{ X ≤ x }
It is called the cumulative distribution of probability of X.
This function is defined even for discrete numerical random variables. For instance, for our wheel with sectors,
F($100) = 61.1%
because it is equal to Pr{ X = $70 } + Pr{ X = $80 } + Pr{ X = $100 }.
But for discrete numerical RV the cumulative distribution of probability is not a very interesting function.
On the contrary, for continuous random variables F(x) is very useful.
F is a function that increases from 0 to 1, since it represents increasing probabilities.
For the random variables we will meet in this course, the cumulative distributions of probability will always be nice smooth functions.
Here is an example of graph of a cumulative distribution of probability F :
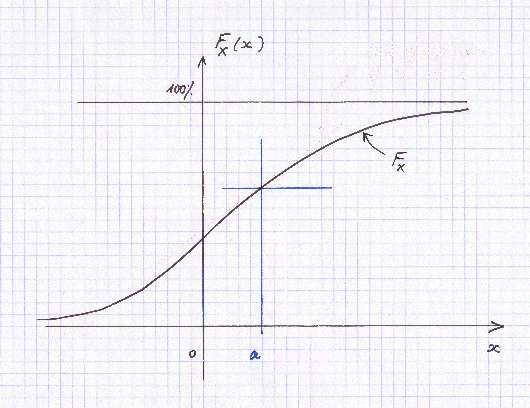
For any point "a" on the abscissa, F has a value F(a).
René Descartes (1596-1650) is usually credited with being the first mathematician to have invented such a representation of a function.
But in fact the idea is already very clearly expressed in the work of Nicolas Oresme (born in 1322 or 1323, died in 1382), almost three centuries before : (stated in modern language) "when a quantitiy y is a function of another quantity x, if we display all the x values along a horizontal axis, and for each x we raise vertically a point above x at a height y, we get a very interesting curve : it somehow represents the relationship between the y's and the x's".
Nowadays we just call this curve "the graph of the function".
The slope of F and the density of probability f :
Except for teratologic random variables that don't concern us in the course, the function F is nice and smooth.
At any point [a , F(a)] there is tangent straight line to F (in red in the graph below)..
We shall be very interested in the slope of this tangent straight line. This slope at "a" is also called "the rate of variation of F at a".
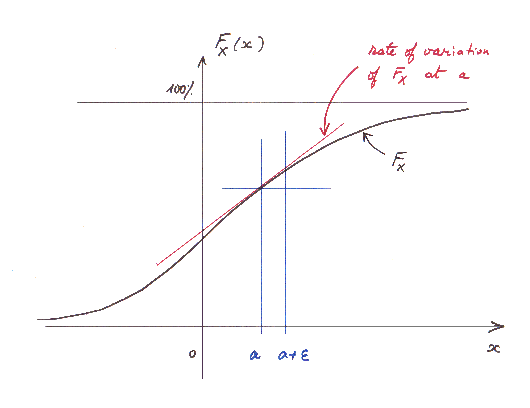
On this graph, for instance, at the point [a , F(a)], the slope of the tangent is about 0.7.
This means that if "a" moves to a point "a + ε" close by, F(a) moves to a value F(a + ε ) ≈ F(a) + 0.7 times ε.
Here is a magnified view of what happens around the point [a , F(a)] :
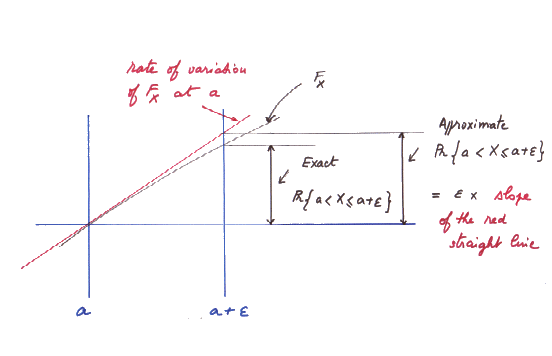
The rate of variation of F at the point [a , F(a)] is denoted f(a). The precise definition of the function f is
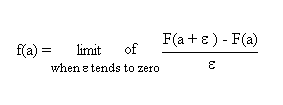
This function f is also called "the derivative of F".
The interesting point about it is that f is the density of probability of X around the value of the outcome "a".
Indeed
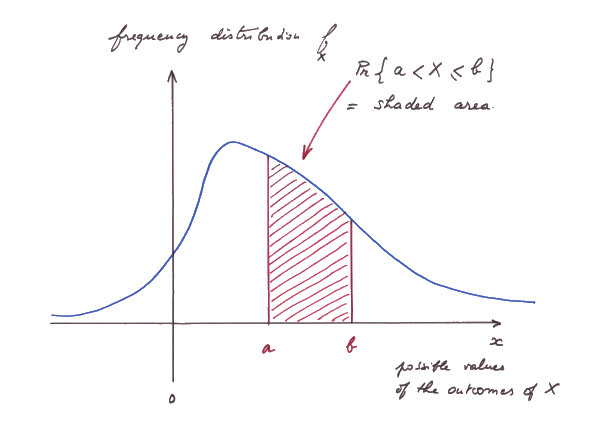
Pr { a < X ≤ a + ε } ≈ ε times f(a)
This is exactly the definition of a density. In fact we are all quite familiar with the concept of density. For those of you who like Physics, remember that a pressure can be viewed as a density of force at a given point. The notion of density is useful because, when considering, for instance, the pressure on the wall of a vessel, the forces vary from area to area (for instance from top to bottom), and the force at any "punctual" point is zero, so a concept of density is useful. This is the role of pressure in Physics.
The notions of density, intensity, pressure, slope, etc. are all the same : a quantity divided by the size of a small vicinity, which gives a local rate of the quantity. Examples : salary per hour, slope of a trail, pressure on a surface, flow of water in a tube per unit of time, mass per volume, speed, even variation of speed over time, etc.
The inverse process, going from rates to a global quantity, i.e. multiplying a rate by the size of a small vicinity to obtain a quantity over a small vicinity, and summing this up over many small vicinities to obtain a global quantity, like going from a density of probability function to the probability of X falling into a segment a to b, will also be of interest to us.
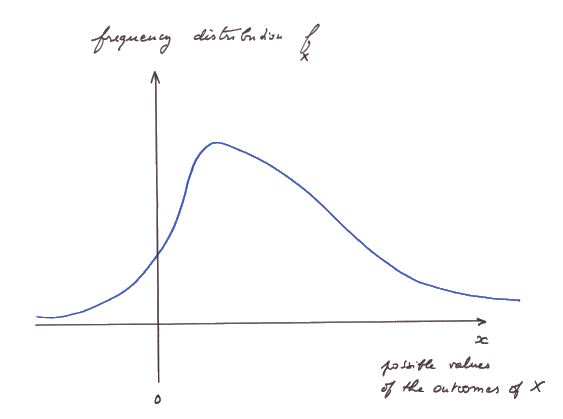
So, for a continuous random variable X we shall be concerned with its density of probability at any possible outcome a , because the concept of Pr{ X = a }, that we used for discrete random variables, has become useless (it is always zero).
Here is the graph of f for X (also called its "frequency distribution") :
We are now in a position to point out the nice relationship between tangents and surfaces :b
This is the fundamental result of Calculus :
for any nice and smooth function F, if we denote its derivative f (that is the slope of the tangent of F at any point), then the area under f between a and b is F(b) minus F(a).
(In truth, it is the definition of the area under f between a and b, because in elementary geometry we only defined areas of rectangles and other simple figures, but this is a long story that does not concern us here.)
In other words, and more loosely speaking, the operation of determining a tangent and the operation of determining an area are inverse operations.
Secondly, if two functions F1 and F2 have the same derivative f, they must be either equal or differ by a fixed constant.
We can readily see this because the function F2 - F1 has everywhere a tangent that is horizontal.
| We can state in another more punchy way the fundamental
result of Calculus :
The rate of variation of the surface area S(x) under a curve f, between 0 and x, is precisely f(x). And, surprisingly enough, this result often lends itself to an easy calculation of the numerical value of S(x). (Illustration in the next section.) |
This nice result escaped ancient Greek mathematicians.
They were only able to compute areas of simple geometric figures. For more complicated figures they usually were not able to compute areas.
Why did not they realize the deep and nice link between tangents and surfaces ? Probably because most of them were profound Realists. Plato, who exposed his apparently subtle ideas about the cave and the shadows, believed in a "true reality", and therefore in a unique form. They could not conceive that some variable quantity could at the same time be represented as a surface area and as a curve. It took the freedom of abstraction of the Nominalists of the late Middle-Ages to shatter this wall.
It was not until Newton and Leibniz (XVIIth century) that the link was definitely elucidated and Calculus could be launched. But this link was already clearly understood by Oresme (XIVth century).
Every great idea is built upon previous great ideas.
Greek mathematicians were great at the geometry of simple figures in the plane, for instance triangles about which they knew just about everything, with the exception of Morley result, discovered only in 1899 ! (Take any triangle, cut each angle with lines into three equal parts, the six lines intersections form an equilateral triangle. In fact Morley result has a deep meaning as regards the links between geometry and algebra : see for instance Alain Connes's proof of Morley's result, published in 1998.)
And precisely, Greek mathematicians did not use algebra. It is the arabic word al jabr (meaning something like "to put back in place", arabic speaking people will correct me), introduced for the first time by author al-Khwarizmi, in his book "Kitab al-Jabr". Al-Khwarizmi (780-850), whose name gave "algorithm", lived in Baghdad in the early IXth century.
Illustration source: http://www.silk-road.com/maps/images/Arabmap.jpg
Because Greek mathematicians did not use algebra, they could not reach the more free attitude toward mathematical concepts necessary to invent Calculus. Greek mathematicians accepted to consider ideal figures (like the triangle) but required that they looked like things they readily saw with their eyes. They did not realize that "what they readily saw with their eyes" was just the result of mental constructions every human being carries out in his early youth, and that those are to an extent arbitrary as long as they model efficiently what we perceive.
Simply stated : Geometry does not come from perceptions ; it is the other way around. Our perceptions, as we think of them in our mind, result from the organizing process we apply to them with the help of usual 3D geometry. This question was already addressed by Kant, and other philosophers. No definitive answer was ever offered (which is, customarily, the mark that the whole framework within which the question is posed ought to be revamped). The most profound answer, in our opinion, is that of Wittgenstein in his "Tractatus logico philosophicus" (who declared : "Wovon man nicht sprechen kann, darüber muß man schweigen").
Since we are all alike we build more or less the same conceptions (this is true only for the simpler shared ideas, not for more personal views). Maria Montessori (1870-1952) understood this, and it lead her to recommanding new ways of organizing kindergartens and educating babies. Some of her ideas every nanny knows who gives her set of keys to the baby to play. It also lead to modern Fisher-Price toys, which are different from those available in 1900. (The next generation of toys will be even more remote from a "representation of reality" because it is unnecessary, misleading and mistaken.)
The more free attitude necessary to make progress was reached little by little by certain thinkers of the Middle-Ages (not all of them), after a large mix of cultures coming from the late Greeks, the Indians, the Sassanids, the Arabs, and some others, took place in the Old world, between years 0 and 1000.
This map offers a breathtaking view of the evolution of civilizations between -1000bc and now. (Time in abscissa, and, more or less, Regions of the Wold along the ordinate axis. From bottom up it corresponds- with the exception of Egypt - to East to West, which is the general movement of populations, in historical times, on Earth.) :
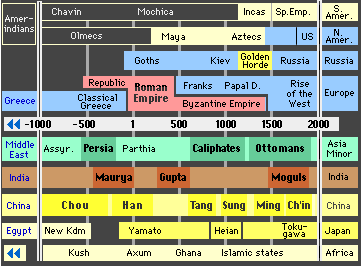
Source : http://www.hyperhistory.com/online_n2/History_n2/a.html
All this lead to the freedom of thinking that was one of the hallmarks of the Nominalists of the XIVth century. Together with the slow diffusion of "al-jabr" in the West, it finally made possible the inventions of Descartes, Newton et alii.
In fact it lead to the more general renewal of attitude toward knowledge and human Arts known as "the Renaissance". But it took a long way, and a long preparation, and the revolutionary ideas of people like Roger Bacon (1214-1294) or William of Ockham (c1285-1349), to name just a few of the most memorable ones (here is a longer list of my favorite ones), to come to bloom. The times preceding "the Renaissance", from 400 to 1400, were anything but dark ages.
In the XVIIth century, the urge to figure out how to compute any kind of area in geometric figures became very strong because, among other examples, Kepler (1571-1630), while studying very precise observations of the movements of planets made by Tycho Brahe, had discovered that a planet going around the sun sweeps equal areas in equal times.
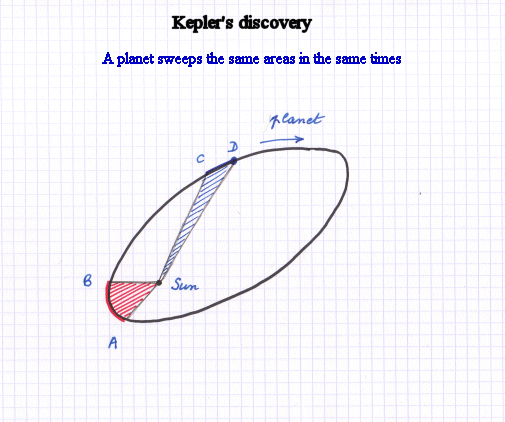
The red shaded surface and the blue shaded surface, if they are sweept in equal times by the planet, have the same area.
Usefulness of the fundamental result of Calculus :
You may wonder so far "OK, these are nice manipulations of mathematical expressions, but why is it useful ?"
Answer : it is useful because quite often it enables us to actually numerically compute an area under a curve.
It applies in a much larger context that just densities of probabiliy. It applies to any "nicely behaved" function (the vast majority of functions used in Finance, Economics, Physics, etc.)
Here is an example of a function f. I chose a simple one. It has a simple explicit mathematical expression : we take x and we square it. It is called a parabola. Suppose we want to compute the blue shaded area under it :
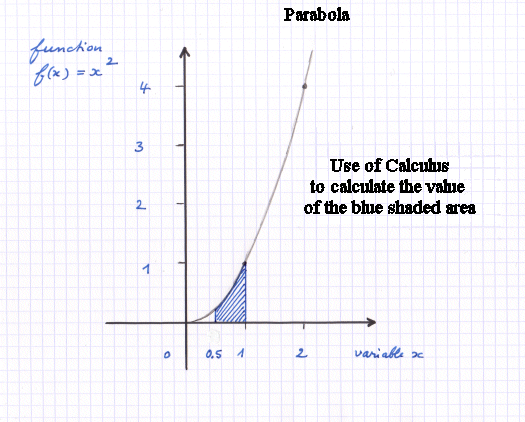
It is easy to verify that the function f(x) = x2 is the rate of variation of the function F(x) = x3/3.
x3/3 is called "a primitive" of x2.
So the surface under f(x) = x2 between 0.5 and 1 is
13 / 3 - (0.5)3 / 3 = 7 / 24
So the blue shaded area ≈ 0.29
Brief recap :
A function F whose derivative is f, is called a primitive of f.
I mentioned casually that a function f cannot have two wildly different primitives F1 and F2. They can only differ by a constant.
We can think of and draw functions for which we don't have a mathematical expression to calculate them. But of course it is nicer to deal with functions for which we have a mathematical expression to calculate them.
There is a special class of such functions that are particularly simple. They are called polynomials. To go from the variable x to the value of the function we only use additions, subtractions, and multiplications. For instance : x -> f(x) = 2x3 -5x +8
Since polynomials are a simple class of functions, it is natural to apply to them the limit process that is so useful all over mathematics.
By a limit process applied to polynomials we mean for instance this : take
the following sequence of polynomials
x
x-x3/6
x-x3/6+x5/120
x-x3/6+x5/120-etc.
(the dividing factor of x2n+1
is the product of the integers from 1 to 2n+1)
Well, the limit of this
sequence of polynomials turns out to be a very interesting function in the mathematics of the
circle, it is called sine of x.
The limit process applied to polynomials yields a large harvest of interesting functions, objects and results. It occupied a good part of the mathematics of the XVIIIth century. And it made mathematicians suspect that there were unifying principles at work to be identified. This lead, in the XIXth century and the XXth century, to a branch of mathematics called Topology, and its rich extensions. Why is it called Topology ? Because to talk about a "limit process" in a space of objects we need to have a notion of distance, so we need to be working in spaces with some sort of topographic structure, "where one can always find one's bearings", and where "to get close to something" has a meaning. The collection of numbers is strongly structured. A collection of socks of various colors is not. The best we can hope for is that we can find pairs :-) The name "topology" was retained for this branch of mathematics.
We also get plenty of interesting functions (useful to represent all sorts of phenomena) when we enrich the permitted operations to division : for instance x -> g(x) = (2x + 3)/(x-1) ; these are called homographic functions and have nice geometric properties.
Then fractional powers are another natural step. For example :
Another direction of extension is : functions of things more complicated than one number. And also functions whose values are not simple numbers, etc.
It is customary in high school to explain the simple, though heavy handed, machinery of relationships between one set of values and another set of values, and then... stop when things begin to get interesting. It makes for pupils that don't understand why studying all that has any interest...
It is very easy to compute the derivative of any polynomial function of x. In particular the derivative of powers are simple :
the derivative of f(x) = x2 is 2x. Indeed the slope of the tangent to the parabola, at the point x = 1, is 2. This has a very concrete meaning : if I move a little bit away from 1 on the x axis, by an amount e, the point on the parabola will move vertically by an amount 2e.
More generally speaking the derivative of xn is nx(n-1).
The derivative of xn/n is x(n-1).
By listing all sorts of derivatives we actually are also constructing a list of primitives of course !
The primitive of x2 is x3/3.
The surface area S(x) between 0 and x under a function f is a primitive of f.
So if for some reasons we have at our disposal another primitive F(x), of the function f, from a list, or from any other origin, we know that S(x) and F(x) can only differ by a constant !
So S(b) - S(a) is necessarily equal to F(b) - F(a).
This is exactly what we did with the parabola above :
This calculation is exact. It's a beauty. The general principle was developped only in the middle ages and after.
Before the advent of computers, to compute an area under a curve f, for which we had an explicit expression, it was necessary to figure out an explicit expression for its primitive F. There are plenty of techniques taught in school to arrive at F. There are also books listing primitives all sorts of functions. When I was a pupil, finding in a book the primitive to the function we had been asked to integrate was like finding in our Latin dictionary the entire text extract we were toiling upon, translated as an example of use of a word ! For instance the primitive of
f(x) = (1 - x) / (1 + x)
is
F(x) = -x + 2 Log(1 + x)
Now computers can numerically compute F(b) minus F(a) for any function f that "we enter into the computer", without needing an explicit expression for F.
And there also exist formal integrators, for instance http://integrals.wolfram.com/
Example : the primitive of f(x) =
(a+b x+c x^2+d x^3)/(1+x^4)
is F(x) =
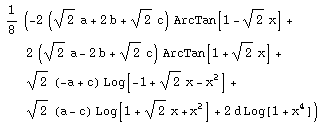
In other words if we draw the curve of F(x), the slope of the tangent to F at any point [x, F(x)] is given by the expression of f(x).
Leibniz introduced his notations in Calculus (they are different from those of Newton), and they are now almost universally employed :
for any function f(x), he noted its derivative
![]()
I don't like this notation because it suggests that the derivative is a ratio and that we can work on the numerator and the denominator like we do with ratios. But the derivative is not exactly a ratio and the suggested manipulations are not always correct.
For the area S under f between a and b, Leibniz also introduced a notation :
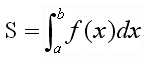
It reads "integral of f from a to b".
Here again this notation, beside some advantages, has great defects : it suggest that it is a sum of separate terms and that when applying an operator to S we can compute the result by applying the operator to f and integrate, which is not always the case.
In Mathematics many concepts or "objects" are defined as limits of a series of other objects. For instance : the real numbers, many functions, and areas. Since we are often interested in applying an operator to these limit objects, it is natural to wonder whether we can apply the operator to the elements of the series and apply the limit process (which can itself be viewed as an operator) to the transformed elements by the operator. Sometimes it is OK (most of the time for "well behaved" objects), sometimes not. Some technical chapters of "higher mathematics" are just concerned with studying in which general settings we can do it. They don't really encompass as powerful ideas as the derivation/integration of Newton and Leibniz.
One last word on areas under curves.
Calculus was developped in the XVIIth century independently by Newton and Leibniz. (They spent a large part of their lives disputing who had invented it first.) Then Calculus was greatly extended by other mathematicians in the XVIIIth and XIXth centuries (the Bernoulli family, Euler, Lagrange, Cauchy, Riemann, Lebesgue, etc)
But as early as the middle of the XIVth century Nicolas Oresme had figured out that if we consider the relationship between the speed of an object moving on a line and the time, and we draw a curve representing this relationship (with time on the abscissa axis and speed on the ordinate axis), then the area under the curve between time t1 and time t2 is the distance covered by the object in the time interval.
Oresme was a friend of French king Charles V, who named him bishop of Lisieux, in Normandy, in 1377.
Oresme also made great contributions to the understanding of money. A few years before his birth, the king of France was Philippe le Bel, who is remembered, among other things, for having discreetly reduced the quantity of gold in coins to try to get more money for the State.
Before becoming bishop Oresme headed for several years the Collège de Navarre, founded in 1304, by Philippe le Bel's wife, Jeanne de Navarre. The college was suppressed by the French revolution. Then, in 1805, Napoleon installed the recently created Ecole Polytechnique in the same premises. It staid there until 1976, when it moved to Palaiseau.
A digression within the digression :
Do not mix up great ideas and technical manipulations. Once the mathematician Stan Ulam, surprised by the "lack of interesting results in Economics" asked the economist Paul Samuelson "Can you tell me one non obvious result in Economics ?" Samuelson thought for a time and then came back with the answer : "The theory of comparative advantage of Ricardo". He was indeed quoting a great idea, as opposed to technical manipulations (that in Economics are particularly simple). By the way Ricardo's idea is indeed remarkable, but it belongs to classical economics, a description of economic phenomena that is still too simplistic (too Realist... One could also say too "Mechanistic". Nominalism hasn't yet reached economics, but in fact it took ten centuries to penetrate mathematics, and the work is not completely finished !).
In mathematics, Calculus presented above is a great idea that took four or five centuries to come to fruition. It was then extended in the XIXth century to spaces more convenient than the real numbers, to start with : the complex numbers. Complex numbers extend the usual real numbers so that polynomial equations always have solutions. Eg : x2+1=0 has solutions in complex numbers. Mathematicians introduced complex numbers in the late XVIth century. It took them many centuries to become accustomed to their new creatures, and at first they called them "imaginary numbers". That was still the name often given to them when I was a kid ! Scholars proceeded just like they did with the negative integers, that were little by little introduced in the Middle-Ages (after the introduction of the zero by Indian author Brahmagupta, in 628). Negative integers eventually came to be accepted as natural mathematical objects, and not just "tricks", so that the equation x + m = n have a solution no matter what m and n are (no restriction to n > m anymore). Calculus with complex numbers is a field of surprising unity and beauty (if we restrict ourselves to functions f(z) that can be "directly" calculated from z), almost entirely developed by one man, Augustin Cauchy (1789-1857).
Of course negative numbers cannot be used to count how many apples there are in a basket, but they can be used for many other things, to begin with they are useful to record what we owe someone else. Double-entry accounting was developed around the XIth and the XIIth century, way before negative numbers were introduced. So in Accounting, to represent sums owned as well as sums owed, instead of positive and negative numbers, we use two columns. But the trick was going to blossom into a concept. The modern notation -x was only introduced in the XVIth century ! (See : history of symbols.) Accounting has kept to its old notation ; it has proved convenient, and accountants are - rightly - a conservative bunch.
To confer to an operation that at first was considered a trick the new status of "deep concept" is a circumstance commonly met in Science, not only in Mathematics. A particularly striking example is the way Max Planck, in 1900, solved a physical riddle called the ultraviolet catastrophe : he introduced what, to him, amounted to a trick, but then, over the next few years, people understood that he had in fact illuminated physics with a deep new concept and so doing had invented quantum mechanics, a new description of reality the marvels of which we are to this day still uncovering.
The introduction of new objects and concepts in Mathematics has most of the time been the fact of users as opposed to pure theorists. This was still the case in the XXth century with "distributions" or with "renormalisation" for instance. I remember reputed mathematicians telling me, in 1981, that physicists were doing "impossible things" in some of their calculations. They were talking just like people criticizing Tartaglia four centuries before ! New procedures or objects or concepts were always the subjects of heated debates between their creators and philolosophers, or other mathematicians that did not take part in the creation process :-) For instance the great philosopher Hobbes wrote in several places that Wallis, who participated in the invention of Calculus, was out of his mind !
Calculus, also called Integration, was refined again around the turn of last century (Borel, Lebesgue, Riesz, Frechet, etc.). But it was essentially technical then, to clarify and simplify and extract the gist of some facts. Don't be mistaken : for instance Riesz theorem, stating that linear operators on functions in L2 can always be represented as F(f) = ∫fdm, is the complicated looking statement of a simple geometrical evidence. (One looks first at the effect of F applied to simple functions fa,n worth 1 in the vicinity of a, and zero elsewhere. It gives m. Then any f in L2 is the limit of simpler functions constructed with the fa,n's. And in that space the operators ∫ and "limit" can be inverted. Remember : many mathematical objects are defined as limits of simpler things. That is why Topology came to play such a role in modern maths.)
XXth century mathematics introduced many great ideas, that are of course more remote from common knowledge than those of the previous centuries. For instance mathematicians discovered a deep link between two types of objects they used to study separately, elliptic functions (that extend sine and cosine) and modular forms. This link lead to the solution of a long standing claim by Fermat, by transforming a problem expressed in one setting into a problem expressed in the other setting, for which a solution was found. This is a common way to proceed in mathematics. One could argue it is the way mathematics proceed. Another illustration, among many, that I like, is the beautiful idea of the turn of last century that links the validity of certain long known results in classical Geometry (Pappus, c290-c350, who lived in Alexandria about the time of the Emperor Theodosius the Elder, Desargues, 1591-1661, born in Lyon at the end of the religious wars in France) with the algebraic properties of multiplication in the underlying spaces in which Geometry is considered. Geometry can be studied in fancier spaces than our usual 3D world :-) Probably toys of the future will make this easy to grasp to kids. These ideas of the XXth century sound arcane - that's why I mention them here - but in fact all they require to become familiar with them is practice, just like a cab driver knows his city very well, while a stranger will be at first lost. By the way there is a nice study of the brain of cab drivers published on the BBC website.
Most people afraid of mathematics were just normal kids, that were frightened by their math teachers, that did not themselves have a clear view of their subject.
It took a long time to mathematicians to understand that the concepts and figures they were working with were constructs in their minds first, applied then to perceptions, and not the other way around. In fact they come first from the construct of the integers : one, two, three, etc. There are two apples in this basket ; there are three powers organizing a democracy, etc. Adding the zero, as a "legitimate member" of the same collection, was only done in the VIIth century. All this was finally clearly undestood at the time of Hilbert around the end of the XIXth century.
Trying to force one's preconceived ideas onto situations that do not fit is very common : for instance we can open many accounting books which state that "computing the unit cost of a product in a multi-product factory is very difficult." But in fact it is not "very difficult", it just has no absolute definition, it is an ad hoc procedure, using trite allocation keys, with some aim in view (for instance establish a price list).
Of course when we grow up we build in our mind the ideas of lines, planes and stuff like that (mostly because we interact with adults who use the same models). They seem very "natural" because the description of natural perceptions with these constructs works well (only to a point). But they don't come from Nature. It is the other way around : Nature is well described with these concepts. I can "demonstrate" geometric problems with the help of pictures on a piece of paper because the piece of paper, as I use it, is a good model for the usual geometry. In fact I really use the pictures as "short hands" for logical statements in English.
One has to be careful though. For instance : if we take a square piece of cloth of side 1 meter and use it to measure the area of a large disk on Earth of radius 1000 km, then we will discover that the area we measured is less than Pi times the square of 1000km. Ok, we will have an explanation, and this will still be explanable within a nice simple "Euclidean space"... But we changed our original view that said : it ought to be Pi times the square of the radius !
The "usual 3-D space" is nothing more than the far consequence of intellectual constructions with integers, multiplication etc. Thales was one of the first to formalize spatial ideas with numbers : he pointed out that figures, when we multiply everything by 2, keep the same shape (an observation that men had made long before Thales, probably more than 40 000 years ago, but they did not care to note it...), and that, with some further precautions, parallels stay parallels, etc.. Fine ! But this is a mental construct, just like saying that there must be two photons to make interferences is a mental construct. By the way this last one had to be abandonned ; quantum mechanics, and more specifically modern quantum mechanics introduced the concept of fundamental non discernability of certain trajectories until we operate some check.
There is no need to abandon the usual 3-D space, as well as other "very abstract" spaces or objects we work with to describe Nature (to start with : random variables), but it is important to note that they are all on the same footing : they are constructions in our minds, extending the basic notion of integers.
When we understand all this we begin to take a different view of many problems of humankind : communication, death, individuality, space, what is shown in the Picasso painting below, etc. It's great fun !

This is a vast and beautiful subject that can be approached by the layman in the books of William Feller (1906-1970) "An introduction to probability theory and its applications" Vol I and Vol II.
I will mention only one fact. The density of probability at a value y of a Gaussian with mean m and standard deviation s is given by the formula
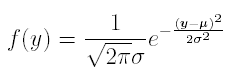
There is no closed form expression for the primitive of this function. But there are tables giving Pr{Y≤y} for values of μ, σ, and y.
And of course, nowadays, there are computers :
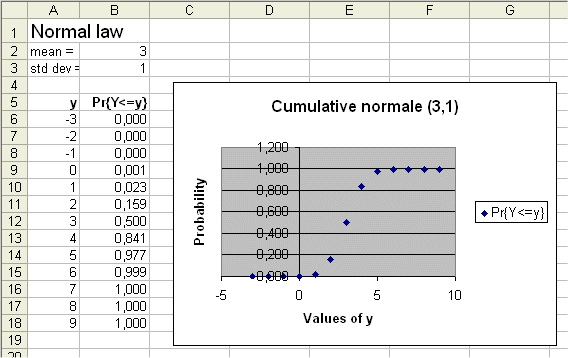
We will not use calculus on densities of probabilities in this course. But we should be aware of the formula above.
We will meet discrete versions of bell curves obtained from establishing histograms.
One point we ought to know about RV and their distributions of probabilities is this :
That is precisely for the same kind of reasons that Calculus is so universally used in Physics, Economics, Finance and many other fields.
It is one illustration of the ambivalent relationship between "discreteness" and "continuity" :
For instance it is easier to deal with the function x-> f(x)=1/x and its integral ∫1 to x f(y)dy = log(x), which with some practice is simple, than with the sequence 1, 1/2, 1/3, 1/4, etc. and its sum S i=1 to n 1/i which remains messier.
The only things we must remember concerning the probabilistic behavior of a continuous random variable are :
Around some outcomes the density of probability will be high, and around other possible outcomes it will be low.
We denote f the function which is the densitiy of probability of the random variable X.
Even though we won't use calculus in this course, we should remember that
Pr{ a < X ≤ a + ε } = ε times f(a)
As we mentioned above, this is the natural definition of a density.
We shall see how, from a series of past outcomes of X, we can estimate the density f around any point. It will be exactly as intuition suggests..
The graph estimating f will be called a histogram. (More on the subject in lesson 4.)
How to estimate the density f of a continuous random variable X :
(The density f is also called the "frequency distribution" of the random variable X.)
We shall work with the 73 outcomes of the profitability of a portfolio of large US industrial firms that I gave you.
How to estimate the density of probability of X ?
The idea is fairly simple and natural : we shall split the range of possible values of X into intervals of equal small width (but not too small) and count how many outcomes fell in each interval.
This will give us a good approximate idea of the density of probability of X around any possible value.
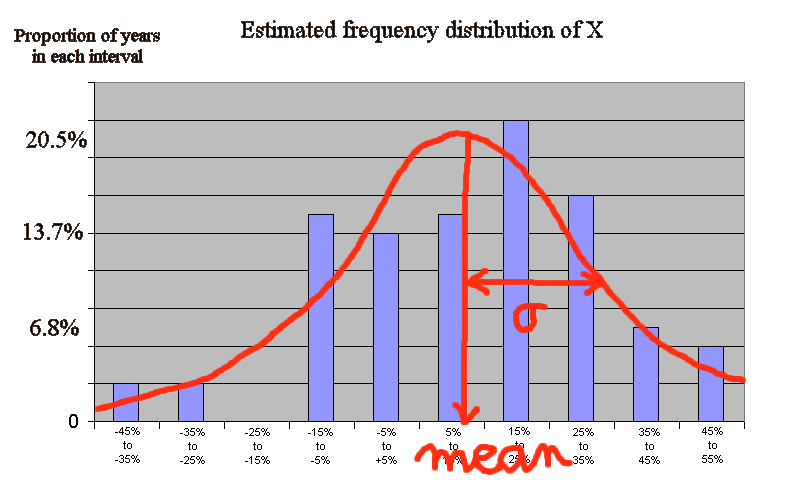
We saw that the 73 outcomes of X fell within -43.76% and 53.12%. So let's consider for instance all the intervals of width 10, going from -45 to + 55, to work with round numbers.
How many outcomes fell within -45% and -35% ? Ans. : 2 (year 31 and year 37)
How many outcomes fell within -35% and -25% ? Ans. : 2 again (year 30 and year 74)
How many outcomes fell within -25% and -15% ? Ans. : 0
How many outcomes fell within -15% and -5% ? Ans. : 11
How many outcomes fell within -5% and +5% ? Ans. : 10
How many outcomes fell within +5% and +15% ? Ans. : 11
How many outcomes fell within +15% and +25% ? Ans. : 16
How many outcomes fell within +25% and +35% ? Ans. : 12
How many outcomes fell within +35% and +45% ? Ans. : 5
How many outcomes fell within +45% and +55% ? Ans. : 4
Now let's plot these figures :
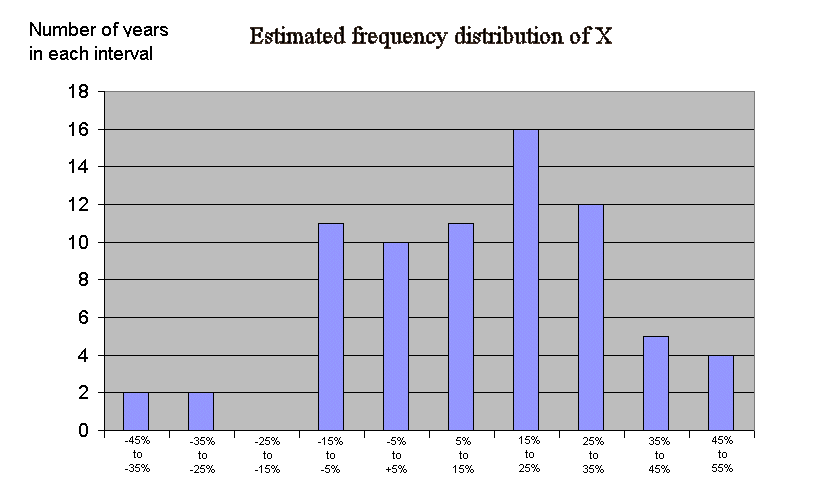
The first remark is that we see a bell curve taking shape, just like in the experiment

We know that this is not surprising : most RV met in Finance have a bell shaped distribution because they are the result of many additive effects.
Relationship between uniform distributions and bell shaped curves :
We may wonder why we get a bell shaped curve ?
Why the values in the middle are more probable than the values at the extremes ?
There is no deep mystery in here. It is really just the result of a counting process.
Think of a long series of random values, x1, x2, x3,... xn, each of them being either +1 or -1 with probability 1/2.
There are 2n such series. Each series has the same probability 1 / 2n .
Now sum up the xi's. We get the result of a discrete random variable S that can take the values
-n, -(n-2), -(n-4), ... ... , +(n-2), +n
There is only one series of xi's that produces S = +n
Identically there is only one series that produces S = -n
But there are n series that produce S = n - 2
There are n(n-1)/2 series that produce S = n - 4
etc.
So to get S = n - 2 is much more probable than to get S = n . To get S = n - 4 is even more probable, etc.
That is how, from a uniformly distributed choice of series of xi's, we end up with a bell shaped curve.
In fact it is in a disguised manner the same distinction as between a simple average and a weighted average. (If we reproduce our series of n xi's, say a thousand times, and want to study the probabilistic behavior of the sum of the xi's, we can either average simply the all the sums of our 1000 series, or we can compute a weighted average of the possible sums weighted by the frequency of their occurences.)
A histogram estimates a density of probability :
The above histogram obtained from sorting out the 73 outcomes into ten intervals, is a collection of 10 numbers, the sum of which is 73.
So if we rescale each of the ten counts by dividing it by 73, we get a collection of 10 estimated probabilities, adding up to 1, as it should.
Let's think of the "true" underlying frequency distribution of the continuous random variable X.
We don't know this true distribution, because we are in the left column of our table of four situations (see above), where we only have access to past history, as opposed to the right column situations where we knew the real underlying distributions and where in fact knowing on top of that a past history of outcomes was irrelevant.
The best thing we can do now is estimate the true underlying density of X : the red curve adjusted onto the histogram is this best estimate.
The estimated expectation of X (also called estimated mean of X) is, naturally enough, the simple average of the 73 outcomes : 13.07%
It can be readily "read" from the graph. (All sorts of statistical methods have been developed to exploit the past history of outcomes, see for instance bootstrap).
We also see from the graph the notion of spread of X (called σ). It is an important number that measures how variable X is. It will also be how financiers define the risk of a security. The number σ will be studied in the next lecture.
Choosing the width of the intervals when drawing a histogram :
When we have a past series of outcomes of X and we want to draw a histogram of these outcomes, we have the choice of how crude or how fine the histogram will be.
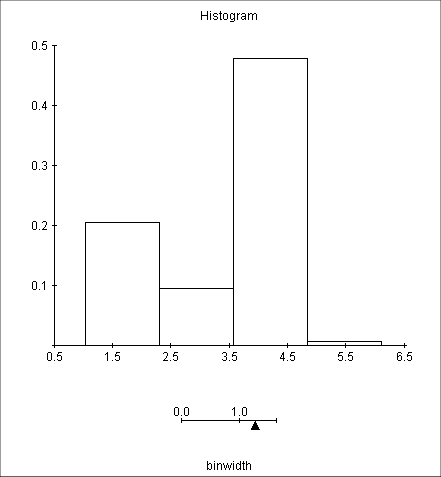
If we choose too large intervals, we will get one or two big sticks and this will tell very little about the actual density of X.
If, on the other hand, we choose them too thin, in each of them we will end up with either one or zero outcome, and it won't be very helpful either.
So choosing the right size our intervals must be done with care.
Here is a java applet showing the effect of the choice of interval size on the histogram of a set of outcomes : http://www.stat.duke.edu/sites/java.html (section "histograms")
Intervals too thin :
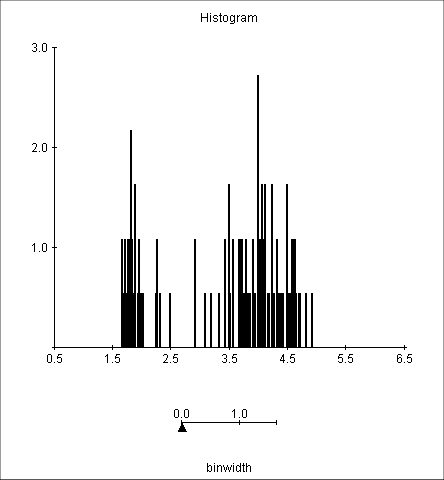
Intervals too wide :
Good size intervals :
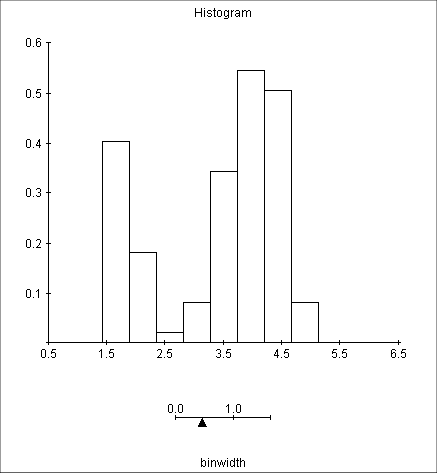
Choosing the "right size" of intervals can be made into a mathematical optimization procedure of some objective, but for us suffices to say that we should, if necessary by by trial and error, make "the histogram look nice".
Transforming a continuous RV into a discrete one :
Choosing intervals to draw a histogram of a continuous RV by counting the number of occurences falling into each interval, really amounts to transforming the initial continuous RV into a discrete one.
Suppose that to each of the 73 initial outcomes we associate a new outcome which is the center of the interval where it falls. This is a variety of rounding up. For instance the exact profitability of the year 1932 is -8.40% -> we round it up to -10%.
Then the initial continuous random variable X is transformed into a simpler discrete one Y that can take the possible values
-40%, -30%, -20%, -10%, 0%, 10%, 20%, 30%, 40% or 50%
Exercise : Check with a spreadsheet that the estimated mean of Y is very close to the estimated mean of X.
Since all the random variables we shall deal with in Finance can be rounded up with no loss of useful information, it is sufficient to have a good understanding of discrete random variables to follow this course in Finance.
{kind=link}